
Python の pandas ライブラリが提供する pandas.DataFrame はテーブル形式データを保持していますが、ここから部分的なデータを抽出する方法がたくさん用意されています。
サンプルデータ
最初に、後述の説明のためにサンプルデータを用意しておきます。
次のコードでは、10 行 3 列のデータを持つ pandas.DataFrame を生成しています。
import numpy as np
import pandas as pd
data = np.random.randn(10, 3) # 10x3 の NumPy 配列を生成(標準正規分布の乱数)
indices = pd.date_range("2010-01-01", periods=10) # 日付の連番からなるインデックスを生成
columns = ("A", "B", "C") # カラム名
my_dataframe = pd.DataFrame(data, index=indices, columns=columns)
print(my_dataframe)
A B C
2010-01-01 -1.083348 0.780602 -1.249351
2010-01-02 -0.421893 1.417954 2.196932
2010-01-03 -1.129684 -0.751984 0.920735
2010-01-04 -0.668949 -2.082924 -0.018011
2010-01-05 1.542745 -1.014717 -0.587786
2010-01-06 0.535100 -0.680070 0.630020
2010-01-07 0.563422 0.856276 1.343315
2010-01-08 1.586091 -1.304232 -1.084707
2010-01-09 -1.561553 -1.884124 0.849059
2010-01-10 -0.817422 -1.244994 0.143166行方向(インデックス)で絞り込んで抽出する
先頭/末尾の数データのみ抽出する (DataFrame#head, DataFrame#tail)
DataFrame オブジェクトの head メソッドや tail メソッドを使用すると、巨大なデータフレームから、先頭あるいは末尾の数データのみを抽出することができます。
最新のデータを取得したいときや、データ構成を簡単に把握したいときに便利です。
戻り値の型は DataFrame です。
print(my_dataframe.head(3)) # 先頭の 3 つのデータのみ抽出 => DataFrame
print(my_dataframe.tail(3)) # 末尾の 3 つのデータのみ抽出 => DataFrame
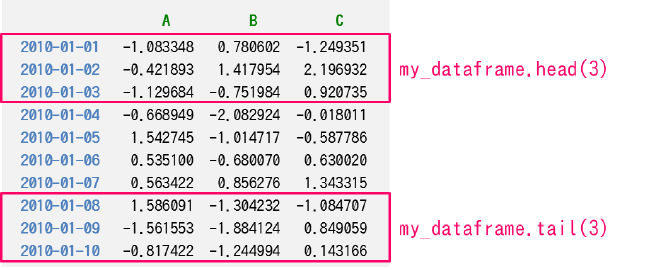
A B C
2010-01-01 -1.083348 0.780602 -1.249351
2010-01-02 -0.421893 1.417954 2.196932
2010-01-03 -1.129684 -0.751984 0.920735
A B C
2010-01-08 1.586091 -1.304232 -1.084707
2010-01-09 -1.561553 -1.884124 0.849059
2010-01-10 -0.817422 -1.244994 0.143166head や tail のパラメータを省略すると、デフォルトで 5 つ のデータが抽出されます。
インデックスの範囲指定でデータを抽出する
DataFrame を参照するときに、Python のスライス構文を使って、インデックス番号やインデックス名で範囲を指定すると、その範囲の部分データを抽出することができます。
単一のインデックス指定ではなく、どのケースも範囲指定になっていることに注意してください。
戻り値は DataFrame オブジェクトです。
print(my_dataframe[0:3]) # 先頭の 3 つのデータを取得
print(my_dataframe[:3]) # 同上
print(my_dataframe[-2:]) # 末尾の 2 つのデータを取得
print(my_dataframe["2010-01-05":"2010-01-07"]) # インデックス名で範囲指定

特定のインデックスのデータを抽出する
DataFrame の loc メソッドを使用すると、特定のインデックスのデータのみを Series オブジェクトとして取得することができます(配列風に 1 つのラベル名だけを指定してアクセスすると、インデックス名ではなくカラム名を指定したことになってしまうので(列方向の抽出)、インデックス名を指定するための loc が用意されています)。
print(my_dataframe.loc["2010-01-01"]) # 特定インデックスのデータを取得 => Series
print(my_dataframe.iloc[0]) # 番号指定の場合は iloc を使う => Series
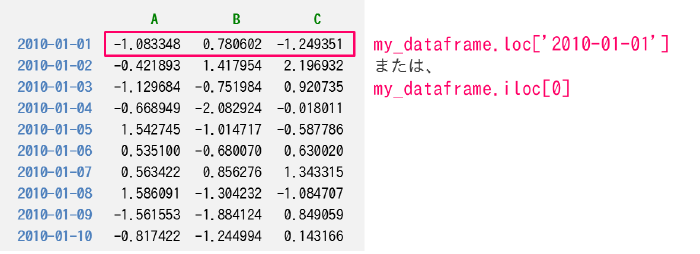
A -1.083348
B 0.780602
C -1.249351
Name: 2010-01-01 00:00:00, dtype: float64DataFrame ではカラム名だった A, B, C が、戻り値の Series データではインデックス名になっていることに注意してください。
列方向(カラム)で絞り込んで抽出する
特定のカラムのデータを抽出する
DataFrame オブジェクトの [] 演算子でカラム名を 1 つだけ指定すると、そのカラムのすべてのデータが pandas.Series データとして抽出されます。
戻り値は、指定した列のみデータを含む 1 次元データなので pandas.Series 型になります。
[] 演算子で単一の値を指定すると、インデックス(行)ではなく、カラム(列)の指定だとみなされることに注意してください。
逆に、インデックスを 1 つだけ指定して特定の行を抽出するには、loc["インデックス名"] や iloc[インデックス番号] を使用する必要があります。print(my_dataframe["C"]) # => pandas.Series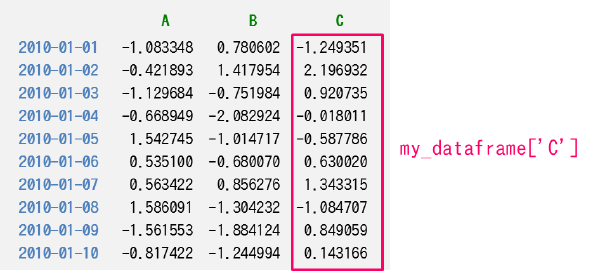
2010-01-01 -1.249351
2010-01-02 2.196932
2010-01-03 0.920735
2010-01-04 -0.018011
2010-01-05 -0.587786
2010-01-06 0.630020
2010-01-07 1.343315
2010-01-08 -1.084707
2010-01-09 0.849059
2010-01-10 0.143166
Freq: D, Name: C, dtype: float64特定のカラムのデータを Series ではなく、DataFrame として抽出するには次のようにします。
print(my_dataframe[("C")]) # => pandas.DataFrameこの記法では、複数のカラムを指定することもできます。
print(my_dataframe[("A", "C")]) # カラム名 A と C の全データを取得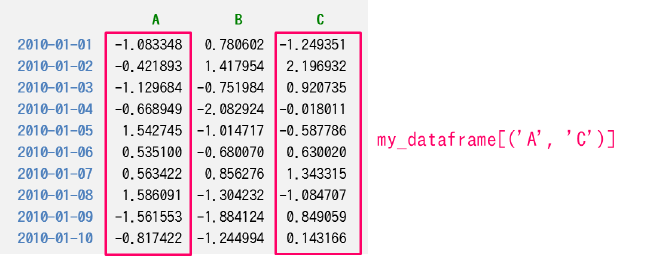
インデックスラベルとカラムを両方指定して取得 (loc, iloc)
DataFrame の loc[] で、インデックスとカラムの範囲を組み合わせて指定することができます。
戻り値の型はデータの抽出範囲によって変化する ことに注意してください。
取得結果が 1 次元データとなる場合は Series オブジェクト、2 次元データとなる場合は DataFrame オブジェクトとなります。
# 単一インデックス + 単一カラム指定 => numpy.float64
print(my_dataframe.loc['2010-01-01', 'A'])
# 単一インデックス + 複数カラム指定 => pandas.Series
print(my_dataframe.loc['2010-01-01', ['A', 'C']])
# インデックス範囲指定 + 単一カラム指定 => pandas.Series
print(my_dataframe.loc['2010-01-01':'2010-01-03', 'A'])
# 全インデックス指定 + 複数カラム指定 => pandas.DataFrame
print(my_dataframe.loc[:, ['A', 'C']])
ラベルではなく、インデックス番号で指定する場合は、loc[] の代わりに iloc[] を使用します。
# 先頭のデータ => pandas.Series
print(my_dataframe.iloc[0])
# 先頭から 3 つのデータ => pandas.DataFrame
print(my_dataframe.iloc[0:3])
# 先頭のデータの 2 つ目のカラムの値 => numpy.float64
print(my_dataframe.iloc[0, 1])
# 全データの 3 つ目までのカラムのデータ => pandas.DataFrame
print(my_dataframe.iloc[:, 0:3])