統計解析やグラフプロットに便利な R 言語のメモです。
R のコーディングスタイル
下記は Google が採用している R のコーディングスタイルを参考にしています。
- インデントはスペース 2 文字
- 一行 80 文字まで
- 代入は
<-を使用する(=は代入には使わない) attachは使わない- エラーの生成には
stop()を使う - S3 オブジェクトを使う(S4 オブジェクトを使わない)
- 命名規則
- 関数:
FunctionName - 変数:
variableName - 定数:
kConstantName
- 関数:
R 環境の Locale 設定(日本語を使用する)
R コンソールを起動したときに、システムの Locale 設定が正しく行われていないと、下記の様な警告メッセージが表示されます。
During startup - Warning messages:
1: Setting LC_CTYPE failed, using "C"
2: Setting LC_COLLATE failed, using "C"
3: Setting LC_TIME failed, using "C"
4: Setting LC_MESSAGES failed, using "C"
5: Setting LC_MONETARY failed, using "C"
[R.app GUI 1.66 (7060) x86_64-apple-darwin13.4.0]
WARNING: You're using a non-UTF8 locale, therefore only ASCII characters will work.
Please read R for Mac OS X FAQ (see Help) section 9 and adjust your system preferences accordingly.R コンソールで正しくメッセージ表示を行うには、少なくとも UTF-8 を使用する設定を行っておく必要があります。
Mac でシステムの Locale 設定を変更する
Mac のターミナルで defaults コマンドを使用すると、システムの Locale 設定を変更することができます。
ヘルプメッセージなどを日本語にしたい場合は、js_JP.UTF-8 の方を指定してください。
$ defaults write org.R-project.R force.LANG en_US.UTF-8 # 英語表示
$ defaults write org.R-project.R force.LANG ja_JP.UTF-8 # 日本語表示
上記を実行してから R コンソールを立ち上げ直すと、正しく Locale 設定が反映されます。 あるいは、R コンソールから下記の様に設定することもできます。
> system("defaults write org.R-project.R force.LANG ja_JP.UTF-8")
locale コマンドを実行すると、現在の設定を確認することができます。
> system("locale")
LANG="ja_JP.UTF-8"
LC_COLLATE="ja_JP.UTF-8"
LC_CTYPE="ja_JP.UTF-8"
LC_MESSAGES="ja_JP.UTF-8"
LC_MONETARY="ja_JP.UTF-8"
LC_NUMERIC="ja_JP.UTF-8"
LC_TIME="ja_JP.UTF-8"
LC_ALL=
ヘルプの使い方
help.start()help(function)
?functionargs(function)> example(mean)
mean> x <- c(0:10, 50)
mean> xm <- mean(x)
mean> c(xm, mean(x, trim = 0.10))
[1] 8.75 5.50上記で実行されるのは、help(mean) を実行したときに Example の項目で示されているサンプルコードです。
?"for"
help("for")??keyword
help.search("keyword")RSiteSearch("keyword")R の構文
条件分岐
if (cond1) {
...
} else if (cond) {
...
} else {
...
}
繰り返し
for (i in 1:5) { ... }
while (cond) { ... }
repeat { ... }
ループ内では break(ループ処理の終了)や next(次のループ処理へ)を使用することができます。
より詳しく調べるには
if や for などの詳しい説明を読みたい場合は、下記のようにヘルプを表示することができます(これらのキーワードは、ダブルクォーテーションで括る必要があることに注意してください)。
?"if"
help("if")
R のデータ型
実数 (numeric)
x <- 12.34
複素数 (complex)
x <- 1+2i
文字列 (character)
x <- 'Hello'
x <- "Hello"
論理型 (logical)
x <- TRUE (or T)
x <- FALSE (or F)
T と F は、TRUE と FALSE の代わりに使用することができますが、別の値を代入してしまうことができます(T と F は定数ではなく変数ということ)。
そのため、公式ドキュメントでは、常に TRUE と FALSE の方を使うことを推奨しています。
ベクトル
x = c(1, 2, 3)
ベクトル内に複数の型を含めると、文字列>実数>論理値 の優先度で同じ型になるように自動的に変換されます。
> c(1, 2, 3.14)
[1] 1.00 2.00 3.14
> c(1, 2+3i)
[1] 1+0i 2+3i
> c(123, TRUE, FALSE)
[1] 123 1 0
> c("ABC", 123, TRUE)
[1] "ABC" "123" "TRUE"
mode 関数で型を調べる
mode() 関数を使用すると、指定した値を、R がどのような型とみなしているかを調べることができます。
> mode(10)
[1] "numeric"
> mode(1+2i)
[1] "complex"
> mode('Hello')
[1] "character"
> mode(TRUE)
[1] "logical"
> mode(c("ABC", 123, TRUE))
[1] "character"
R スクリプトファイルを実行する (source)
例えば、commands.R というテキストファイルに R のコマンドを記述してある場合、以下のように読み込んで実行することができます。
> source("commands.R")
読み込み時のカレントディレクトリは、getwd() で取得、setwd() で変更することができます。
R コマンドの実行結果をファイルに保存する (sink)
R コマンドの実行結果はデフォルトではウィンドウ (console) 内に表示されますが、sink() 関数で出力先をファイルに切り替えることができます。
> sink("output.txt")
出力先をウィンドウ (console) に戻すには、パラメータ無しで sink() 関数を呼び出します。
> sink()
現在作成されているオブジェクトの一覧を表示する (ls, objects)
Java や C++ の変数にあたるものは、R ではオブジェクトと呼びます。
現在作成されているオブジェクトの一覧を確認するには、ls() あるいは objects() を使用します。
> x <- 1:10
> y <- x**2
> ls()
[1] "x" "y"
> objects()
[1] "x" "y"
上記の結果表示されたオブジェクトは、下記のように「参照」できます。
> x
[1] 1 2 3 4 5 6 7 8 9 10
> y
[1] 1 4 9 16 25 36 49 64 81 100
不要なオブジェクトは、rm() で削除することができます。
> ls()
[1] "x" "y"
> rm(x)
> ls()
[1] "y" # x が削除された
R の実行環境を終了するとき、現在作成されているオブジェクトは、カレントディレクトリの .RData というファイルに保存されます。
Windows 環境では、この .RData ファイルをダブルクリックすることで、終了時と同じ状態で R を起動することができます。
このような仕組みがあるため、分析の対象ごとにディレクトリを作成しておくと便利です。
出力先を画像ファイルに切り替える
R では 「作図デバイス」 を切り替えることによって、plot() や hist() による描画内容を画像ファイルとして保存することができます。
現在の環境でどのような形式をサポートしているかは下記のように確認できます。
help("Devices")
PNG ファイルへの出力
たとえば、PNG ファイルにプロットするには下記のように png() 関数を使用して作図デバイスを切り替えます。
描画が終わったら、dev.off() で作図デバイスを閉じます(閉じないとファイルが使用中のままになってしまい、別のアプリケーションから開くことができません)。
png("output.png", width=400, height=300) # 作図デバイス(png)を開く
plot(x, y) # 描画
dev.off() # 作図デバイス(png)を閉じる
作図デバイスを切り替えるときに、bg="transparent" オプションを指定すると、背景を透過した画像 を出力することができます。
> png("sample.png", width=400, height=300, bg="transparent")
> plot(x, y)
> dev.off()
SVG ファイルへの出力
svg() 関数を使用すると、グラフの出力先を SVG ファイルに変更することができます。
svg() 関数の width、height パラメータの単位は、デフォルトで インチ となっていることに注意してください(png() 関数の場合はピクセルです)。
svg("output.svg", width=4, height=3) # 作図デバイス(svg)を開く
plot(x, y) # 描画
dev.off() # 作図デバイス(svg)を閉じる
こちらの場合も、実際の SVG ファイルは、dev.off() してからアクセスできるようになります。
ファイルの出力先ディレクトリ
どこに画像ファイルが出力されたかを調べるには、getwd() を使用します。
> getwd()
[1] "C:/Users/maku/Documents"
このワーキングディレクトリは setwd() により変更可能です。
> setwd("C:/your/dir") # スラッシュを使う場合
> setwd("C:\\your\\dir") # バックスラッシュを使う場合
この setwd() は柔軟にできており、次のようにして 1 つ上のディレクトリに移動することもできます。
> setwd("../")
データ生成
連番のベクトルを作成する (seq)
コロンを使用した範囲指定により、連番要素からなるベクトルを簡単に生成することができます。
x <- 1:5 # c(1, 2, 3, 4, 5) と同様
x <- 5:1 # c(5, 4, 3, 2, 1) と同様
下記のように、ついでに演算を行うことで柔軟なベクトル生成を行えます。この例では、1, 2, 3 というシーケンスのそれぞれの要素に +1 したシーケンスを生成しています。
x <- (1:3)+1 # c(2, 3, 4) や 2:4 と同様
ちなみに、演算子 : は、+ よりも結合度が高いため、上記の例のカッコを省略しても同様に動作します。
x <- 1:3+1 #=> 2, 3, 4
上記の結果は、ちょっと直感に反するかもしれません。
演算子 + を先に評価するには、次のようにする必要があります。
x <- 1:(3+1) #=> 1, 2, 3, 4
seq() 関数を使用すると、より柔軟にシーケンスデータを生成できます。
下記の例では、0.1 刻みのデータを作成しています。
x <- seq(from=0, to=0.5, by=0.1) #=> 0.0, 0.1, 0.2, 0.3, 0.4, 0.5
len パラメータを使うと、何分割するかを指定することができます。
下記の例では、-π~π の範囲の値を 100 等分して得られるシーケンスデータを生成しています。
x <- seq(-pi, pi, len=100)
plot(x, sin(x))
ちなみに sin 波は plot(sin, -pi, pi) とすることで滑らかに描画できます。
繰り返しのベクトルを作成する (rep)
rep() 関数を使用すると、すでに存在するベクトルデータ内の要素を繰り返したベクトルデータを作成することができます。
> x <- 1:3
> rep(x, times=5)
[1] 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3> x <- 1:3
> rep(x, each=5)
[1] 1 1 1 1 1 2 2 2 2 2 3 3 3 3 3ベクトルに対して算術演算を行う
ベクトルに対してスカラ値の算術演算を行うと、各要素に対して演算 が行われます。 結果的に、元のベクトルと同じ数の要素のベクトルが作成されます。
> x <- c(1, 2, 3)
> x + 100
[1] 101 102 103
> x - 100
[1] -99 -98 -97
> x * 100
[1] 100 200 300
> x / 100
[1] 0.01 0.02 0.03
> x ^ 2
[1] 1, 4, 9
スカラ値に作用する算術系関数をベクトルに適用した場合も、ほぼ同様の振る舞いをします。
下記の例では、ベクトルの各要素に対して log10() を適用しています。
> x <- c(1, 10, 100, 1000)
> log10(x)
[1] 0 1 2 3
この性質を利用して、下記の様に x 軸のベクトルデータから、y 軸のベクトルデータを作成するという使い方ができます。
x <- 1:5 # 1~5 までの連番データを生成 (1, 2, 3, 4, 5)
y = x^2 # 各要素の二乗からなるデータを生成 (1, 4, 9, 16, 25)
plot(x, y) # 二次元グラフとしてプロットこの例では y というオブジェクトを作成していますが、プロット系の関数に渡す時に直接データ生成してしまうこともできます。
plot(x, x^2)
他にもいろいろな演算や関数を組み合わせてデータを生成することができます。
plot(x, 1+sqrt(x))
ベクトル同士の演算を行う
ベクトル同士の算術演算を行うと、対応する各要素ごとに算術演算が行われます。
> x <- c(1, 2, 3)
> y <- c(100, 200, 300)
> x + y
[1] 101 202 303
> x - y
[1] -99 -198 -297
> x * y
[1] 100 400 900
> x / y
[1] 0.01 0.01 0.01
要素数の異なるベクトル同士で算術演算を行うと、少ない方の要素が繰り返し参照 されます。
> x <- c(1, 2)
> y <- c(100, 200, 300, 400, 500, 600)
> x + y
[1] 101 202 301 402 501 602
要素数がちょうど整数倍になっていないときは警告が出ます。
> x <- c(1, 2)
> y <- c(100, 200, 300)
> x + y
[1] 101 202 301
Warning message:
In x + y : longer object length is not a multiple of shorter object length
2 つのデータを結合する (c)
任意の数のベクトルを結合するには c() を使います。
a <- 1:3
c(a, a) #=> 1, 2, 3, 1, 2, 3
c(a, a*2) #=> 1, 2, 3, 2, 4, 6
c(a, a^2) #=> 1, 2, 3, 1, 4, 9
c(a, a, 7) #=> 1, 2, 3, 1, 2, 3, 7
ベクトルの各要素にプレフィックス、サフィックスを付ける (paste)
paste 関数を使用すると、2 つ以上のベクトルデータの各要素を文字列結合したベクトルデータを生成することができます。
サイズの異なるデータを与えた場合、少ない方のデータが繰り返し適用されます。
これを利用して、ベクトルの各要素にプレフィックスやサフィックスを付けることができます。
> paste('A', 1:3)
[1] "A 1" "A 2" "A 3"上記のように、デフォルトではスペースを挟んで結合されます。
セパレータは sep パラメータで変更できるので、次のように空文字列を指定することでスペースを挟まずに結合することができます。
> paste('A', 1:3, sep='')
[1] "A1" "A2" "A3"
paste() 関数に渡すベクトルの順序を変更すれば、サフィックスを付加することができます。
> paste(1:3, 'x', sep='')
[1] "1x" "2x" "3x"3 つ以上のベクトルを結合することもできます。 次の例では、3 つのベクトルを結合して連番からなるファイル名を作成しています。
> paste('data', 1:5, '.zip', sep='')
[1] "data1.zip" "data2.zip" "data3.zip" "data4.zip" "data5.zip"
ベクトルのサイズを切り詰める、拡張する (length)
length() 関数を代入の左辺に持ってくると、ベクトルのサイズを変更することができます。
現在の要素数よりも小さいサイズを指定すれば切り詰めることになり、大きいサイズを指定すれば拡張することになります。
拡張された部分の要素の値は NA となります。
> x <- 1:10
> x
[1] 1 2 3 4 5 6 7 8 9 10
# サイズを切り詰める
> length(x) <- 5
> x
[1] 1 2 3 4 5
# サイズを拡張する
> length(x) <- 10
> x
[1] 1 2 3 4 5 NA NA NA NA NA
ベクトルのサブセットを生成する(ベクトルのフィルタ)
ベクトルデータに対して、[] 演算子を使って インデックスベクトル (index vector) を指定すると、そのベクトルの要素を特定の条件で組み合わせたベクトルを作成することができます。
インデックスベクトルに指定するベクトルの型により、動作が変わります。
- 数値ベクトル(
1 〜 length(x)の範囲の数値で構成されるベクトル)を指定した場合- 指定した要素位置で構成されたベクトルを作成
- 論理ベクトル(
TRUE,FALSEで構成されるベクトル)を指定した場合TRUEになる位置の要素のみで構成されたベクトルを作成(フィルタ)
インデックスベクトルとして数値ベクトルを指定する
下記は、数値ベクトルで示した位置の要素から構成されるベクトルを作成しています。
> x <- c('A', 'B', 'C')
> x[c(1, 2, 3, 2, 1)]
[1] "A" "B" "C" "B" "A"
Python のリスト(配列)と同様のインデックスアクセスや配列スライシングを行えるのは、この仕組みのおかげです。
> x <- c('A', 'B', 'C')
> x[2]
[1] "B"
> x <- c('A', 'B', 'C')
> x[2:3]
[1] "B" "C"
範囲外のインデックスを指定すると、その位置の要素は NA になります。
> x <- c('A', 'B', 'C')
> x[1:5]
[1] "A" "B" "C" NA NA
数値ベクトルを作成する関数(rep() など)と組み合わせて使用することで、柔軟なベクトル作成を行うことができます。
> x <- c('A', 'B', 'C')
> x[rep(c(1, 2, 2), times=3)]
[1] "A" "B" "B" "A" "B" "B" "A" "B" "B"
負の数値からなる数値ベクトルを渡すと、その位置の要素を削除したベクトルを作成することができます。 次の例では、2 番目と、3 番目の要素を削除したベクトルを作成しています。
> x <- 1:5
> x[c(-2, -3)]
[1] 1 4 5
インデックスベクトルとして論理ベクトルを指定する
下記は、インデックスベクトルとして、論理ベクトルを指定する例です。 この仕組みを使うと、ベクトルから 条件に合致する要素だけを抽出する ことができます。 次の例では、数値ベクトルから偶数のみを取り出しています。
> x <- c(4, 7, 3, 2, 6)
> x[x%%2 == 0]
[1] 4 2 6
内部的には x%%2==0 というところで、以下のような TRUE と FALSE から成る論理ベクトルを作成しています。
TRUE FALSE FALSE TRUE TRUE
この論理ベクトルの中で、TRUE になっている位置(偶数)の要素を抽出していることになります。
ランダムな正規分布を生成する (rnorm)
rnorm() を使用すると、指定した数のランダムな正規分布データを作成することができます。
x <- rnorm(1000)
hist(x, breaks=30)

標準偏差 (standard deviation) はデフォルトで 1 となりますが、sd パラメータで任意の標準偏差を指定することもできます。
x <- rnorm(1000, sd=2)
hist(x, breaks=30)

データフレーム
データフレームとは
データフレームは、カラム名のあるレコードの集まりを表現します。
リレーショナル・データベースのレコードや、エクセルのシートのような表形式のデータを想像すると分かりやすいです。
R の起動時に、デフォルトで women というデータフレームが定義されているので、それを表示してみます(データ数が多いので head 関数を使って、表示数を減らしています)
> head(women)
height weight
1 58 115
2 59 117
3 60 120
4 61 123
5 62 126
6 63 129
height と weight という名前のカラムが定義されていることがわかります。
左側の 1 から始まる数値は、データの行番号を示しています。
データフレームから特定のカラムを抽出する
下記のようにすると、データフレーム内の特定のカラムのみをベクトルデータとして取得することができます。 カラムのインデックス(1 から始まる)あるいは、カラム名で指定することができます。 インデックスを囲む括弧 (bracket) が 2 重になっていることに注意してください。
> women[[1]]
[1] 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72
> women[["height"]]
[1] 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72
> women$height
[1] 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72次の例では別の形式でカラムを指定していますが、このようにすると、指定したカラムのデータがベクトルではなくデータフレームとして返されます。
つまり、データフレームのサブセットを作成していることになります。
c() を使用して、カラムを複数指定することも可能です。
> women[1]
height
1 58
2 59
3 60
...
> women[c(1, 2)]
height weight
1 58 115
2 59 117
3 60 120
...
> women["height"]
height
1 58
2 59
3 60
...
> women[c("height", "weight")]
height weight
1 58 115
2 59 117
3 60 120
...ベクトルからデータフレームを作成する (data.frame)
data.frame 関数を使うと、ベクトルデータからデータフレームを作成することができます。
下記の例では、name と price というベクトルデータからデータフレームを作成しています。
> name <- c("apple", "banana", "strawberry")
> price <- c(200, 100, 300)
> df <- data.frame(name, price)
> df
name price
1 apple 200
2 banana 100
3 strawberry 300
デフォルトでは、パラメータとして渡したオブジェクト名が、そのままデータフレームのカラム名になります。 名前付きパラメータとして渡すことで、任意のカラム名に変更することができます。
> df <- data.frame(n=name, p=price)
> df
n p
1 apple 200
2 banana 100
3 strawberry 300
その他
標準で利用可能な標準データセット一覧を表示する (data)
> data()
Data sets in package 'datasets':
AirPassengers Monthly Airline Passenger Numbers 1949-1960
BJsales Sales Data with Leading Indicator
BJsales.lead (BJsales)
Sales Data with Leading Indicator
BOD Biochemical Oxygen Demand
CO2 Carbon Dioxide Uptake in Grass Plants
ChickWeight Weight versus age of chicks on different diets
DNase Elisa assay of DNase
EuStockMarkets Daily Closing Prices of Major European Stock
Indices, 1991-1998
Formaldehyde Determination of Formaldehyde
HairEyeColor Hair and Eye Color of Statistics Students
Harman23.cor Harman Example 2.3
Harman74.cor Harman Example 7.4
Indometh Pharmacokinetics of Indomethacin
InsectSprays Effectiveness of Insect Sprays
JohnsonJohnson Quarterly Earnings per Johnson & Johnson Share
LakeHuron Level of Lake Huron 1875-1972
LifeCycleSavings Intercountry Life-Cycle Savings Data
Loblolly Growth of Loblolly pine trees
Nile Flow of the River Nile
Orange Growth of Orange Trees
OrchardSprays Potency of Orchard Sprays
PlantGrowth Results from an Experiment on Plant Growth
Puromycin Reaction Velocity of an Enzymatic Reaction
Seatbelts Road Casualties in Great Britain 1969-84
Theoph Pharmacokinetics of Theophylline
Titanic Survival of passengers on the Titanic
ToothGrowth The Effect of Vitamin C on Tooth Growth in
Guinea Pigs
UCBAdmissions Student Admissions at UC Berkeley
UKDriverDeaths Road Casualties in Great Britain 1969-84
UKgas UK Quarterly Gas Consumption
USAccDeaths Accidental Deaths in the US 1973-1978
USArrests Violent Crime Rates by US State
USJudgeRatings Lawyers' Ratings of State Judges in the US
Superior Court
USPersonalExpenditure Personal Expenditure Data
UScitiesD Distances Between European Cities and Between
US Cities
VADeaths Death Rates in Virginia (1940)
WWWusage Internet Usage per Minute
WorldPhones The World's Telephones
ability.cov Ability and Intelligence Tests
airmiles Passenger Miles on Commercial US Airlines,
1937-1960
airquality New York Air Quality Measurements
anscombe Anscombe's Quartet of 'Identical' Simple Linear
Regressions
attenu The Joyner-Boore Attenuation Data
attitude The Chatterjee-Price Attitude Data
austres Quarterly Time Series of the Number of
Australian Residents
beaver1 (beavers) Body Temperature Series of Two Beavers
beaver2 (beavers) Body Temperature Series of Two Beavers
cars Speed and Stopping Distances of Cars
chickwts Chicken Weights by Feed Type
co2 Mauna Loa Atmospheric CO2 Concentration
crimtab Student's 3000 Criminals Data
discoveries Yearly Numbers of Important Discoveries
esoph Smoking, Alcohol and (O)esophageal Cancer
euro Conversion Rates of Euro Currencies
euro.cross (euro) Conversion Rates of Euro Currencies
eurodist Distances Between European Cities and Between
US Cities
faithful Old Faithful Geyser Data
fdeaths (UKLungDeaths)
Monthly Deaths from Lung Diseases in the UK
freeny Freeny's Revenue Data
freeny.x (freeny) Freeny's Revenue Data
freeny.y (freeny) Freeny's Revenue Data
infert Infertility after Spontaneous and Induced
Abortion
iris Edgar Anderson's Iris Data
iris3 Edgar Anderson's Iris Data
islands Areas of the World's Major Landmasses
ldeaths (UKLungDeaths)
Monthly Deaths from Lung Diseases in the UK
lh Luteinizing Hormone in Blood Samples
longley Longley's Economic Regression Data
lynx Annual Canadian Lynx trappings 1821-1934
mdeaths (UKLungDeaths)
Monthly Deaths from Lung Diseases in the UK
morley Michelson Speed of Light Data
mtcars Motor Trend Car Road Tests
nhtemp Average Yearly Temperatures in New Haven
nottem Average Monthly Temperatures at Nottingham,
1920-1939
npk Classical N, P, K Factorial Experiment
occupationalStatus Occupational Status of Fathers and their Sons
precip Annual Precipitation in US Cities
presidents Quarterly Approval Ratings of US Presidents
pressure Vapor Pressure of Mercury as a Function of
Temperature
quakes Locations of Earthquakes off Fiji
randu Random Numbers from Congruential Generator
RANDU
rivers Lengths of Major North American Rivers
rock Measurements on Petroleum Rock Samples
sleep Student's Sleep Data
stack.loss (stackloss)
Brownlee's Stack Loss Plant Data
stack.x (stackloss) Brownlee's Stack Loss Plant Data
stackloss Brownlee's Stack Loss Plant Data
state.abb (state) US State Facts and Figures
state.area (state) US State Facts and Figures
state.center (state) US State Facts and Figures
state.division (state)
US State Facts and Figures
state.name (state) US State Facts and Figures
state.region (state) US State Facts and Figures
state.x77 (state) US State Facts and Figures
sunspot.month Monthly Sunspot Data, from 1749 to "Present"
sunspot.year Yearly Sunspot Data, 1700-1988
sunspots Monthly Sunspot Numbers, 1749-1983
swiss Swiss Fertility and Socioeconomic Indicators
(1888) Data
treering Yearly Treering Data, -6000-1979
trees Diameter, Height and Volume for Black Cherry
Trees
uspop Populations Recorded by the US Census
volcano Topographic Information on Auckland's Maunga
Whau Volcano
warpbreaks The Number of Breaks in Yarn during Weaving
women Average Heights and Weights for American Women
Use 'data(package = .packages(all.available = TRUE))'
to list the data sets in all *available* packages.データが正規分布に従っているかを調べる
Shapiro-Wilk 検定
Shapiro-Wilk の検定は、データが正規分布に従っているかどうかを検定する統計検定の 1 つです。
R では shapiro.test() 関数を使用することで、Shapiro-Wilk の検定を行うことができます。
> shapiro.test(women[["weight"]])
Shapiro-Wilk normality test
data: women[["weight"]]
W = 0.96036, p-value = 0.6986> shapiro.test(trees[["Volume"]])
Shapiro-Wilk normality test
data: trees[["Volume"]]
W = 0.88757, p-value = 0.003579p-value) は、帰無仮説を棄却してしまう「タイプ 1 の誤り」の確率を示しています。
有意水準を 10% とした場合、p 値が 0.10 未満であれば帰無仮説「正規分布に従う」を棄却することができます。
つまり、tree データセットの Volume カラムは正規分布に従っていないと判断できます。Shapiro-Wilk の検定以外にも、Q-Q プロット や ヒストグラム を使ってデータが正規分布に従っているかどうかを確認することができます。
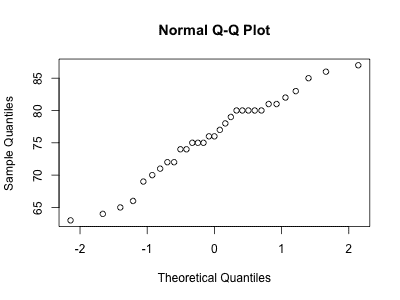
Q-Q プロット
Q-Q プロットは、データが正規分布に従っているかどうかを視覚的に確認するためのグラフです。
R では qqnorm() 関数を使用することで、Q-Q プロットを描画することができます。
> qqnorm(trees[["Height"]])
ヒストグラム
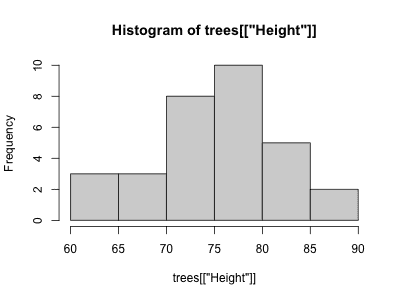
ヒストグラムは、データの分布を視覚的に確認するためのグラフです。
R では hist() 関数を使用することで、ヒストグラムを描画することができます。
> hist(trees[["Height"]])
自己相関関係(1 時点前のデータとの関連をプロットする)
> data <- AirPassengers
> plot(x=data[1:99], y=data[2:100])
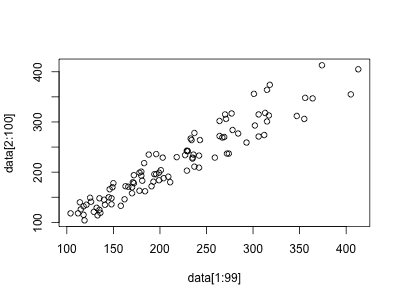
時系列データの自己相関を調べる際に使用します。 データが左下から右上に向かって直線的に分布している場合、1 時点前のデータとの相関が高いことを示しています。 ここでは、1 時点前(ラグ=1)のデータとの関連をプロットしていますが、2 時点前、3 時点前といった関連を調べることもできます。
x 軸にラグ、y 軸に自己相関係数の値をプロットした図を、コレログラム と呼びます。
R ではコレログラムを描画するための acf() 関数が用意されています (ACF: Auto-Correlation Function)。
> acf(AirPassengers, plot=TRUE)
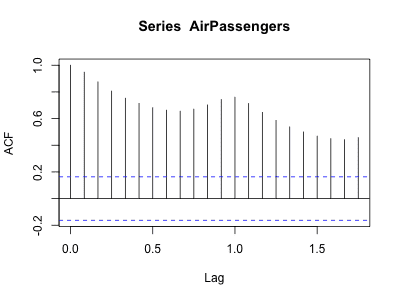
上記のように plot=TRUE(デフォルト)とするとコレログラムを描画し、plot=FALSE とすると自己相関係数の値のみを返します。
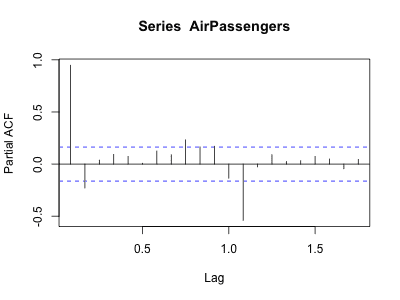
type="partial" オプションを指定すると、y 軸の値を「偏自己相関係数」とすることができます (Partial ACF)。
> acf(AirPassengers, plot=TRUE, type="partial")